이 웹사이트는 국민의 알권리 보장을 위해 대통령기록관에서 보존·서비스하고 있는 대통령기록물입니다.
This Website is the Presidential Records maintained and serviced by the Presidential Archives of Korea to ensure the people's right to know.
이 웹사이트는 국민의 알권리 보장을 위해 대통령기록관에서 보존·서비스하고 있는 대통령기록물입니다.
This Website is the Presidential Records maintained and serviced by the Presidential Archives of Korea to ensure the people's right to know.

인공지능(AI, Artificial Intelligence)은 이제 더 이상 먼 미래의 이야기나 소수 전문가의 영역이 아니다. 이 기술은 우리 눈에 보이지는 않지만, 이미 우리 일상생활 곳곳에 침투해 있다. 우리가 부지불식간에 사용하는 스마트폰 애플리케이션에도 이미 다양한 인공지능 기술이 접목되어 있다.
인공지능이 작동하기 위해서는 알고리즘, 학습에 필요한 데이터, 강력한 컴퓨팅 파워가 필요하다. 이 가운데 알고리즘은 ‘어떤 문제를 해결하기 위한 논리적 절차’로서 컴퓨터가 연산이나 추론을 할 수 있도록 컴퓨터 언어로 구성된다. 인공지능의 알고리즘은 인간의 지성을 모방한 논리 체계이기도 하다.1 마셜 맥루언(Marshall McLuhan)은 인간 신체 기관(organ)의 확장을 미디어로 이해했는데, 그 관점에서 보면 인공지능은 뇌의 기능적 확장이며 미디어 체계라 부를 수 있다. 기계가 사람과 같은 사고방식을 가지고 사람의 행동 방식과 사고를 인식한다면 이를 인공지능이라고 부를 수 있을 것이다.2 즉 인공지능은 인공 두뇌가 인간 두뇌의 인지 기능을 복제하고 수행하는 능력을 말하며, 인공지능의 궁극적 비전은 인간의 두뇌와 같이 복잡성과 유연성을 달성하는 것이다.
인공지능은 기계를 인간처럼 만들었다기보다 인간의 논리를 기계에 적용한 기술이다. 논리는 서양에서 2,500년 동안 이어진 장구한 숙제였다. 기호(symbol)와 규칙(rule)으로 구성된 논리를 통해 인간이 자연을 이해하고자 하는 시도는 수학과 철학의 오랜 과제다. 오늘날 컴퓨터에 적용된 이진법(0, 1이라는 기호로 모든 것을 표현하는 논리 체계)의 기초는 고트프리트 빌헬름 폰 라이프니츠(Gottfried Wilhelm von Leibniz)와 조지 불(George Boole)과 같은 수학자들로부터 출발한다.3
인공지능 역사에서 가장 중요한 인물은 영국의 수학자 앨런 매시선 튜링(Alan Mathison Turing)이다. 그는 논리적으로 참이라는 것을 계산해내는 기계인 가상의 ‘튜링머신’을 1936년에 생각해냈다. 컴퓨터 이론의 출발점이다. 그는 여기서 더 나아가 기호와 규칙만 주어지면 기계가 규칙에 따라 계산을 수행해 계산 가능한 것을 참으로, 못하는 것을 거짓으로 하는 ‘보편적 튜링머신’을 제시했다. 우리가 지금 사용하는 데스크톱 컴퓨터도 이러한 프로그램이 구현되는 기계로 튜링머신의 일종이다. 컴퓨터 산업이 혁명적으로 발전할 수 있었던 것은 이처럼 인간의 논리를 기호와 규칙으로 전환하는 보편적 기술이 존재했기 때문이다. 다양한 프로그램 소프트웨어는 제각각 독립적인 논리 체계를 갖고 있고 과업을 수행한다. 그러나 단순한 컴퓨터 프로그램을 인공지능이라고 부르지는 않는다. 컴퓨터 프로그램은 특정화된 목적에 기반해서 작동된다. 하지만 인공지능으로 무엇을 하겠다는 목적이 우선하는 것이 아니라 구현할 수 있는 능력을 사용자가 원하는 목적에 결합한다. 이 둘을 가르는 핵심적인 차이는 학습 능력에 있다. 인공지능을 소프트웨어적으로 구현하는 방식의 하나가 머신러닝(machine learning)이다. 머신러닝은 컴퓨터가 데이터를 학습해 스스로 패턴을 찾도록 하는 알고리즘을 말한다.4
바둑기사 이세돌을 이긴 딥마인드의 알파고는 바둑 기술을 학습한 기계이지 바둑 게임을 위해 설계된 인공지능이 아니다. 일반 컴퓨터 프로그램은 프로그래머가 의도한 것 이상의 성능을 내지 못한다. 그 때문에 이를 강화시키고자 한다면 인간의 개입이 필요하다. 그러나 알파고와 같은 인공지능은 100만 번 이상의 자체 대국을 거치며 스스로 학습해 기력을 향상한다. 바둑을 배우는 어린아이의 뇌가 바둑에만 적용되는 것이 아닌 것처럼 인공지능은 범용성을 갖는다. 스스로 학습하고 지능을 강화시켜 어떤 문제에도 유연하게 대응할 수 있는 논리 체계, 이것이 바로 인공지능이라고 요약할 수 있겠다.
간혹 인공지능을 휴머노이드 로봇처럼 특정하게 구현된 물리적 기술체라고 오해하는 경우가 있다. 인공지능은 인간의 사고를 모방한 컴퓨터의 기계적 논리 체계로서 스스로 학습하여 판단하는 능력을 갖춘 범용 기술이다. 그렇기에 인공지능은 ‘보이지 않는 기술’이다. 오늘날 인공지능의 발전은 기계 학습에서부터 신경망 모형을 적용한 딥러닝(deep learning)에 이르는 논리적 학습 모형 또는 체계, 다양하고 광범위한 데이터, 컴퓨터의 저장 및 처리 기술, 네트워크 기술 등의 요소 기술이 동시에 발전했기 때문에 가능했다. 특히 5G 이동통신 기술과 같은 초고속, 초연결 기술과 클라우드 컴퓨팅과 같은 서버 기술은 어떤 가벼운 기기라도 인공지능 기술을 접목해 구현할 수 있도록 만들었다. 인공지능 기술 실생활화의 기술적 토대가 마련된 것이다.
인공지능의 범용성은 이 기술이 우리의 삶 곳곳에 적용될 수 있다는 의미다. 최근 구글이 실험하고 있는 인공지능 기술 사례는 인간의 상상력이 미치는 곳 어디에든 인공지능을 접목할 수 있음을 말해준다. 구글은 미국 서부에 73마리밖에 안 남은 것으로 보고된 멸종 위기종 범고래(Orca)를 보호하기 위해 범고래가 내는 독특한 소리를 이미지로 변환한 후, 이를 인공지능으로 분석하여 해안가에 있는 동물 보호 단체에 알려주고 있다. 앞으로 범고래가 내는 소리를 의미론적으로 해석할 날도 얼마 남지 않았다.5 또한 구글은 헬스케어 프로젝트의 일환으로 눈동자만 촬영해 빈혈을 진단하는 기술을 선보였다.6 눈 뒤쪽에 있는 혈관의 패턴을 학습해 빈혈로 인해 안구 내 혈관 변형 패턴을 찾아내는 기술이다. 그동안의 통계적 모형으로는 발견하기 어려웠던 잠재된 패턴을 인공지능은 학습 데이터와 학습 모형을 결합해 찾아낸 것이다.
따라서 학습 기계로서 인공지능은 데이터와 이를 계산하는 적정한 알고리즘, 그리고 컴퓨팅 파워만 있다면 모든 것에 도전할 수 있다. 어린아이가 무엇을 배우는가에 따라 재능이 달라지는 것과 다를 바 없다. 그렇기에 인공지능 기술은 우리의 삶을 감싸는 안개처럼 침습하는 기술이다. 우리는 이 기술을 보거나 만질 수 없지만 여기서 벗어나기 어려운 시대로 진입했다.
인공지능 기술이 가져온 가장 혁신적인 변화는 언어 영역에 있다. “개와 고양이가 나온 이미지 파일을 검색해서 이메일에 파일로 첨부해줘”라는 명령어는 인간에게는 단순하지만, 기계에게는 매우 어려운 작업이다. 이런 복잡한 언어를 기계가 이해하기 위해서는 사람의 음성을 인식하는 기술, 언어 사용자의 의도를 파악하는 기능, 찾고자 하는 실체가 무엇인지를 알아내는 방법, 명령어를 처리하는 방식 등이 모두 동원되어야 한다. 이를 가능하게 한 자연어 처리 기술의 발달은 더 이상 이런 명령어의 처리가 장벽이 되지 않는 수준으로 진전했다.

자연어 처리(NLP, Natural Language Processing) 기술은 컴퓨터와 인간 언어를 연결 짓는 인공지능의 핵심 기능 중 하나다. 1950년대부터 기계 번역과 같은 자연어 처리 기술 연구가 시작되었고, 1990년대를 거치면서 대량의 말뭉치(corpus) 데이터를 활용하는 기계 학습 및 통계적 자연어 처리 기법으로 발전했다. 그러다 최근에는 인공 신경망에 기반한 딥러닝 기술이 접목되어 방대한 언어 텍스트로부터 의미 있는 정보를 추출해 활용하고 있다. 이러한 자연어 처리 기술은 기계 번역, 대화체 질의응답 시스템, 대화 시스템, 정보 검색, 그리고 빅데이터 분석 등 다양한 영역에 걸쳐 활용되고 있다.
기계와 인간의 자연스러운 의사소통 시대가 열린 것이다. 스마트폰 기반의 음성 AI 비서인 네이버의 클로바(Clova), 삼성전자의 빅스비(Bixby), 애플의 시리(Siri), 아마존의 알렉사(Alexa), 구글의 어시스턴트(Assistant), 마이크로소프트의 루이스(Luis) 등은 모두 자연어 처리 기술이 구현된 서비스다. 구두 언어에 익숙한 인간에게 자연어 처리 기술은 기계와 상호작용할 때 기계스럽지 않게 또는 기계임을 인식하지 못하는 수준의 환경을 만들고 있다.
특히 최근의 딥러닝 기술은 자연어 처리 기술을 급속하게 발전시키고 있다. 이 분야에서 가장 앞서 있는 구글은 2016년에 신경망 기계 번역 NMT(Neural Machine Translation)를 적용해 번역의 정확도를 높였다. 이 기술은 번역할 때 개별 단어가 아닌 전체 문장을 보면서 광범위한 언어 소스를 비교 적용하는 딥러닝 방법이다.7 여기서 더 나아가 구글은 2018년 11월에 최첨단 딥러닝 기반 AI 언어 모델 ‘버트(BERT, Bidirectional Encoder Representations from Transformers)’를 발표했다.8 버트는 광범위한 자연어 처리 작업에서 단어의 뉘앙스와 문맥을 보다 잘 이해하고 유용한 검색 결과가 효과적으로 일치하도록 도와준다. 구글 검색 등에 이러한 버트가 접목되면서 사람과 대화하는 방식의 검색 기술이 현격하게 상승했다. 구글 이외에도 마이크로소프트의 루이스 등은 일부 성능 평가에서 인간보다 언어 이해력에서 더 높은 정확도를 보인 자연어 처리 기술 분야 AI의 최첨단 딥러닝 모델이다.
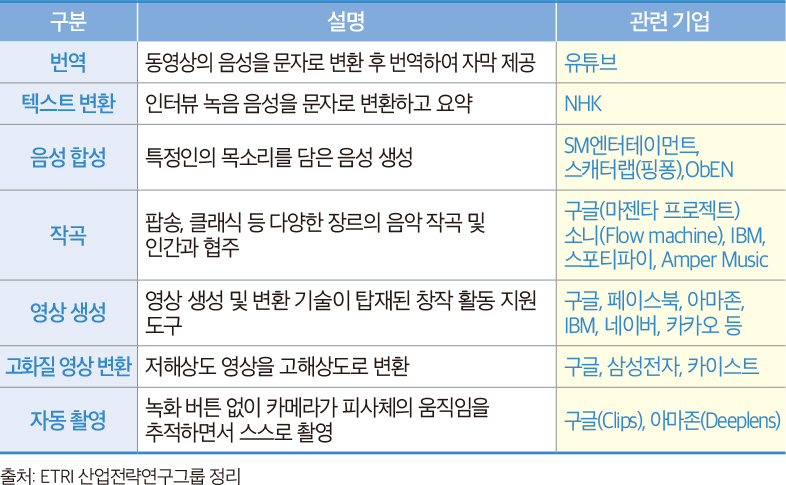
그렇다면 인간보다 더 언어 능력이 우수한 인공지능의 등장이 가져올 우리 삶의 변화는 무엇일까? 첫째는 언어 간 장벽이 없어져 진정한 글로벌 빌리지가 형성된다는 점이다. 《구약성서》의 바벨탑 이야기에서 알 수 있듯이 다른 집단의 언어를 이해하는 건 인류가 오랫동안 고민해온 과제다. 언어의 장벽은 문화와 정보 교류의 큰 장애 요소였다. 그러나 신경망을 기반으로 한 번역 기술은 마이크로소프트 트랜스레이터(Microsoft Translator) 및 스카이프(Skype)의 실시간 번역 기능 등에 이미 적용되고 있다. 구글이 개발한 무선 이어폰 ‘픽셀버즈 2’는 올해 출시 예정인데 이어폰을 꼽은 채로 실시간 언어 통역을 이용할 수 있다. 유튜브의 번역 자막 서비스는 전 세계 모든 콘텐츠를 언어적 이해를 동반해 소비할 수 있게 해준다. 방탄소년단(BTS)의 세계적인 대중화에는 유튜브의 자동 번역 서비스가 큰 몫을 했다.
둘째, 자연어 처리 기술은 원시 부족사회 이래로 인간이 유지해온 커뮤니케이션의 원형인 구두 언어가 지배하는 새로운 커뮤니케이션 시대를 만들게 된다. 트위터와 페이스북, 카카오톡에 널리 적용되는 대화형 인터페이스 챗봇(chatbot)에서부터 자동차나 커피 머신까지 물리적 조작 없이 언어를 통해 조작할 수 있게 됨에 따라 기계는 작동의 대상물이 아니라 생활 보조자로 자연스레 자리 잡고 있다. 구두 언어의 부상은 높은 수준의 인지적 노력과 관여가 필요한 문자 시대를 밀어내고, 이성에서 정서나 맥락을 보다 중요시하는 새로운 소통 문화를 만들 것으로 예상된다.
셋째, 상시적으로 언어 처리 기계의 보조를 받는 증강적 커뮤니케이션 환경이 구현된다. 기계를 통해 인간은 자신이 처해 있는 맥락에 맞추어 외국어를 활용하거나 새로운 정보나 개념을 지원받게 될 것이다. 그뿐만 아니라 온라인에서의 차별, 폭력, 괴롭힘 등을 자동적으로 분류하고 필터링할 수도 있다. 구글과 직소(Jigsaw, 구글의 모회사 알파벳 산하의 스타트업)가 2017년 발표한 ‘퍼스펙티브(Perspective)’는 온라인 댓글 등의 악성 여부를 판단해 필터링하는 기술이다. 현재 <뉴욕타임스> 등 다수 언론사가 자사 홈페이지의 댓글 관리에 이 기술을 접목하고 있다.9
넷째, 자연어 처리 기술은 방대한 데이터를 빠르게 처리할 수 있게 하는 것은 물론이고 영상이나 이미지 분석과 결합해 보다 강력한 의미 해석과 예측이 가능하게 되었다. 한 예로 페리스코픽사가 개발한 ‘트럼프-이모티코스터(Trump-Emoticoaster)’가 있다.10 이 기술은 자연어 처리 기술과 시각 인식 기술을 결합한 것으로 도널드 트럼프 대통령이 사용하는 언어와 표정을 분석해 그의 감정 상태를 파악하는 엔진이다. 인간을 둘러싼 다양한 맥락 정보에서 패턴을 찾아낼 수 있게 됨에 따라 ‘나보다 더 나를 잘 아는 기계’가 등장한 것이다.
인공지능 기술은 초창기부터 추천 시스템에 널리 적용되어왔다. 추천 시스템이란 개인별로 스타일과 선호도를 파악하여 다양한 관점의 성향을 추출하고 이를 학습해 맞춤형 서비스나 콘텐츠를 제공하는 것이다.11 해외에서는 아마존(Amazon), 넷플릭스(Netflix), 스포티파이(Spotify)에서 사용자의 명시적·암묵적 선호도를 분석하여 특정 서적·영화·음악을 추천하는 시스템이 그 대표적인 예라 할 것이다. 국내에서는 왓챠나 멜론과 같은 영화·음악 추천 서비스를 비롯하여 네이버의 ‘에어스(Airs)’, 다음의 ‘루빅스(RUBICS)’와 같은 뉴스 추천 알고리즘을 꼽을 수 있다.
오늘날 추천 시스템은 거의 모든 디지털 서비스에 접목되고 있다. 추천 시스템은 인간의 행동 패턴을 학습해 예측된 값을 바탕으로 특정 상황에 적합한 맞춤형 제안을 하는 서비스다. 그런데 이 시스템은 정보 과부화에 걸린 우리에게 많은 편리함을 제공하지만 개인과 사회적 차원에서 기술에 대한 과도한 의존과 기술이 갖는 편향에 영향을 받는 문제점도 제기되고 있다. 황용석과 김기태(2019)는 인공지능 추천 시스템이 학습된 데이터의 편향성과 알고리즘 모형의 문제로 언제든지 편향이 발생할 수 있다는 점을 방법론적으로 분석했다.
추천 시스템의 편향 문제는 마셜 밴 앨스타인(Marshall Van Alstyne)과 에릭 브린욜프슨(Erik Brynjolfsson)이 1996년에 제시한 ‘사이버 발칸화(Cyber Balkanization)’ 개념과 맞닿아 있다.12 이 개념은 인터넷이 공동체를 위한 소통과 토론의 장을 확대했지만, 비슷한 관심사나 정치적 지향을 가진 사람들끼리의 폐쇄적인 소그룹으로 만들어 공동체를 파편화시킬 수 있다는 의미다. 앨스타인과 브린욜프슨은 이 개념을 제시한 지 약 10년 후에 같은 취지에서 추천 시스템이 비슷한 사람, 정보, 취향을 찾기 훨씬 편리하게 해줌으로써 사이버 발칸화를 가속화시킬 수 있다고 다시 한번 지적한다.13 이들의 지적은 사회심리학에서 언급되는 ‘집단 극화(Group polarization)’ 현상과 유사하다. 집단 극화는 사회심리학에서 집단의 의사 결정이 구성원들 간의 상호작용 이후 개별적인 결정보다 더 극단적인 방향으로 흐르는 현상을 일컫는다. 추천 서비스의 맞춤형 알고리즘은 이러한 집단 극화 현상을 촉진시켜 극단적인 정치적 대립각을 더욱 노골화시킨다.
엘리 프레이저(Eli Pariser)는 페이스북과 구글의 맞춤형 검색 서비스가 개인의 의사와 상관없이 개인의 취향이나 정치적 지향과 맞지 않는 정보를 걸러내(filtering-out) 사람들이 진실의 극히 일부분에 불과한 정보에 둘러싸여 자신만의 세계에 갇혀버리게 되는 현상이 나타난다고 지적했다. 이른바 ‘필터 버블(filter bubble)’ 현상이 그것이다.14
반대로 추천 시스템은 인터넷 공동체의 동질화(homogenization) 혹은 집중화(centralization)를 초래할 수 있다. 전자상거래(e-commerce) 추천 시스템에 대한 연구를 보면, 추천 리스트에 최우선으로 등장하는 아이템이 가장 많은 사람에게 노출되기 마련이고 동시에 가장 많은 사람으로부터 좋은 평가(ratings)를 받는 승자 독식 시스템(winner-take-all-system)도 확인된다.15
인공지능 기술이 인간과 같은 감정과 창의성을 가질 수 있는가에 대해 많은 학자가 논의해왔다. 현재의 기술로 볼 때 감정 또는 정서의 영역은 인공지능이 도전할 마지막 장벽이 될 것이다. 감정을 표현해내거나 대응하는 기술은 가능하지만, 인공지능이 감정을 가졌다는 것은 곧 인간과 동일하다는 것을 의미하기 때문이다.
반면 창의성 영역에서는 새로운 도전과 성과가 나타나고 있다. 2017년 구글은 ‘마젠타 프로젝트(Magenta Project)’의 인공지능 프로그램이 딥러닝을 통해 창작한 음악인 80초짜리 경쾌한 피아노곡을 선보였다.16 스페인 말라가대학교에서 개발한 ‘이아무스(Iamus)’는 사람이 악기 종류와 곡의 길이만 입력하면 스스로 곡을 만드는데, 사람이 작곡한 곡과 이아무스가 만든 곡을 함께 들려주는 실험을 한 결과 음악 전문가를 절반가량 포함한 250명의 청중은 구별에 실패한 것으로 나타났다. 소니 컴퓨터사이언스연구소(Sony CSL)에서는 인공지능에 비틀스나 바흐의 곡을 학습시켜 새로운 비틀스풍, 바흐풍 음악을 작곡하는 것을 시연하기도 했다.
비정형화된 미술 분야도 예외는 아니다. 이미 구글의 인공지능 ‘딥드림(deep dream)’이 만든 그림은 2016 미국 샌프란시스코 갤러리에서 29점이나 팔렸다. 이 중 최고가는 9,000달러에 달하는 등 모두 9만 7000달러의 매출을 올렸다.
인공지능의 도전은 영상, 음악, 회화, 뉴스 등 다양한 분야로 확장되고 있다. 뉴스 기사와 같이 명확한 서사 구조가 있는 스타일의 글을 만드는 것은 상대적으로 기계에게 용이한 창작 작업이다. 저술 분야에서도 괄목할 만한 진척이 있었다. 일본의 쿼리아이(QueryEye)가 만든 인공지능 ‘제로’는 두 권의 책을 학습한 후 ‘성공이란?’, ‘인간이란 무엇을 말하는가?’ 등의 철학적 주제를 담은 《현인강림》이라는 책을 저술하기도 했다.17
인공지능이 창작의 영역에 도전하게 된 것은 뇌의 뉴런과 유사한 정보 입출력 계층을 활용해 데이터를 학습하는 딥러닝 알고리즘 때문에 가능했다. 그 가운데에서도 인간이 정답을 가르쳐주지 않는 비지도 학습인 GAN(Generative Adversarial Network)의 등장은 인공지능이 스스로 새로운 것을 생성하고 창조하는 능력을 갖추었음을 증명했다. GAN은 구글 브레인 연구팀의 이언 굿펠로(Ian J. Goodfellow)18 등이 2014년 제안한 새로운 신경망 모델로서, 우리말로 생성적 적대 신경망이라고 불린다. GAN은 복수의 신경망이 ‘생성자’와 ‘감별자’를 순환적으로 경쟁하면서 판단이 어려운 수준, 즉 ‘실제같이 보이는 허구’의 조건을 만들어낼 수 있는 기법이다. 굿펠로는 생성자를 위조지폐범에, 감별자를 경찰에 비유했다. 생성과 감별이 반복적으로 학습되면서 위조지폐가 점점 정교해지는 것처럼, 이미지를 학습해 실제에 가까운 데이터, 거짓 이미지를 만들 수 있게 된다. 실제로 엔비디아(NVIDIA)는 2017년 GAN을 기반으로 유명인 20만 명의 사진을 학습시켜 실존하지 않는 사람들의 사진을 무한대로 만들어낼 수 있는 기술을 선보이기도 했다.19
GAN은 그 활용성 측면에서 양면적 속성을 갖고 있다. 먼저, 인공지능이 예술과 같은 창의적 결과물을 만들고 있다는 점이다. 이는 기존의 영상 콘텐츠 제작에 혁신을 불러올 것으로 기대된다. 포토샵과 플래시 등 영상 편집 프로그램을 만드는 어도비 연구팀은 UC버클리대학교와 공동으로 GVM(Generative Visual Manipulation)20이라는 기술을 발표했다. 이 기술은 이용자가 간단한 입력 값만 넣어주면 인공지능이 그림을 변경해준다. 인간의 작은 자극만으로도 무수한 새로운 창작 결과물 산출이 가능한 것이다. GAN을 이용한 웹툰 창작은 국내에서도 시도된 바 있다. 네이버는 하일권 작가의 네이버 웹툰 ‘마주쳤다’에서 GAN을 이용해 인물 이미지의 애니메이션화, AR, 얼굴 인식 기술, 360도 파노라마 등을 웹툰에 적용한 바 있다.21

반면 실제와 구분되지 않는 가짜 또는 허구를 통해 사회적 기만행위가 손쉽게 일어난다는 점이 지속적으로 지적되고 있다. 정치인의 입에 다른 사람의 말을 넣거나, 포르노 스타의 몸에 유명 인사의 얼굴을 합성하거나, 경찰의 캠코더 화면을 조작하는 등 딥페이크(deep fake) 영상이 현실 정치에 큰 영향을 미치고 있다. 이미 2017년 8월 미국 워싱턴대학교 연구진은 버락 오바마 전 미국 대통령의 가짜 영상을 만들어 화제가 된 바 있다. 그보다 최근에는 낸시 펠로시 미국 하원의장이 마치 술에 취한 것처럼 조작한 영상을 트위터, 페이스북, 유튜브 등에 게시해 널리 퍼지게 한 사건으로 큰 정치적 파장을 불러왔다.22 실제와 구분되지 않는 허위 조작 정보인 딥페이크의 가장 큰 문제점은 기술적 도구 없이 외견상으로는 진짜와 가짜를 구분할 수 없다는 점이다.
창작 행위와 속이는 행위는 인공지능이 구현된다는 기술적 관점에서는 동일하지만, 사회적 맥락에 따라 다르게 판단될 수 있다. 인간 창의성에 대한 인공지능 기술의 도전은 지식 및 창작 노동을 급속하게 대체하고 있다. 미디어 영역을 보면 기사나 방송 프로그램과 같은 상업적 콘텐츠를 만드는 데 많은 비용과 인력이 필요하다. 그런데 인공지능 기술이 급속하게 이러한 인간 노동을 대체해나가고 있다. 뉴스 소재 발굴, 시나리오 작성, 관계 수 예측 등 기획 과정에도 활용되고 있다. 이미 국내외 언론사에는 로봇 저널리즘이 광범위하게 적용되기 시작했다. 기사 제작에 들어가는 원가를 줄이기 위해 인공지능 알고리즘이 데이터를 분석해 기사를 만들어낸다.23 캐나다의 경제정보업체인 톰슨 파이낸셜(Thomson Financial)의 알고리즘이 기업의 수익과 관련된 기사를 자동으로 생성한 이후 로봇 저널리즘이란 이름으로 전 세계 주요 언론사에 광범위하게 적용되고 있다.
인공지능 기술의 확산은 인간과 인간이 구성한 사회제도가 주도하던 체제에서 비인간 행위자인 기계가 개입하고 관계를 조율하는 체제로 들어섰다는 것을 말해준다. 사회 운영의 주도권이 인간에서 기계로 넘어가는 시발점에 놓인 셈이다.
인공지능 기술이 우리 사회에 가져다줄 편익은 크지만, 반면 그것에 대한 두려움과 우려도 존재한다. 미국 포인터연구소가 최근 발간한 보고서는 인공지능 전문가들이 이 새로운 기술의 영향을 어떻게 생각하고 평가하는지를 잘 보여준다. 주요 전문가들의 인터뷰를 통해 구성한 다섯 가지 우려는 다음과 같다. 첫째, 인공지능의 사용이 개인의 삶에 대한 통제력을 감소시킬 수 있다. 둘째, 주로 효율성과 이익 및 통제를 위해 설계된 감시 및 데이터 시스템이 본질적으로 사회적 가치를 훼손할 위험이 있다. 셋째, 인공지능에 의한 인적 일자리 감소는 경제 및 디지털 격차를 넓혀 사회 격변으로 이어질 수 있다. 넷째, 인공지능에 의존하게 되면 개인의 인지, 사회적 기술과 생존 기술이 감소될 수 있다. 다섯째, 시민들은 통제 불능의 딥페이크 같은 사이버 범죄 및 사이버 전쟁에 대한 노출과 무기화된 필수 정보로 인해 위험에 처할 가능성과 같은 취약성에 직면할 수 있다.25
이 밖에 인공지능에 의존해서 생기는 체계적인 의사 결정의 편향과 그에 따른 진실 또는 사실에 대한 착시 현상의 확대도 우려된다. 인공지능 기술이 사회적 불평등을 강화할 것이라는 주장도 설득력이 있다. 기술이 주는 편익으로 취약 계층의 정보 접근성이 높아지지만 동시에 데이터와 플랫폼을 장악한 소수의 기업과 인공지능을 통제할 수 있는 세계적 기업의 지배력이 강화된다. 인공지능은 빅데이터와 컴퓨팅 파워가 요구되고 플랫폼 경제에서 최적으로 작동된다. 즉 플랫폼을 장악한 기업에 의한 초독점 현상이 나타날 것이다. 인공지능이 사회적 연결을 강화할 수도 있지만, 반면 비대면 문화가 확산되고 사람이 아닌 기계와 소통하는 사회적 고립도 우려된다. 기계와의 상호작용 속에 우리는 외로움과 사회적 관계 형성의 고마움을 잊게 될 수도 있다.
기술이 발달하는 세상에 대한 우리의 시선은 긍정과 부정의 균형점을 유지할 필요가 있다. 외부 효과에 대한 다면적인 사고가 동반되지 않는다면, 우리는 기술에 예속되면서도 그것을 지각하지 못하는 기술 식민화에 처할 수도 있기 때문이다. 결국 기술도 하나의 사회적 제도이기에 인간의 개입 의지와 가치 형성이야말로 중요한 해결책이다. 이를 위한 학문적이고 정책적인 논의가 보다 활발하게 전개되어야 할 것이다.